Hash Objectsを使用してバイナリフラグをカウント
Hash Objectsネタです。
前にも書きましたがHash ObjectsはSASデータセットをキーとデータの単位でデータ構造を持つことができます。既存のSASデータセットの変数をキーにカウントすることはPROC SQL、DATA Stepでも可能ですがHash Objectsのadd()、replace()メソッドを使用することでPDVにない変数をキー、データとして同オブジェクトのホスト変数に動的に追加しカウントをとることができます。例えば以下のケースでも採番が可能になります。
1. クレジットカードの利用額が限度額を超えないイベントをカウントしたい。
2. しかし一回目の限度額を超えないイベントはカウントしない
3. 1、2の条件を判定する変数はデータセットに存在しない
データは下のサンプルデータを使用します。price_markが限度額、priceが利用額です。
1オブザベーション目、2オブザベーション目は限度額を超えないのでカウント1,2となりますが、2の条件に当てはまるのでカウントしません。カウントするのは7、8、9オブザベーションからとなります。この処理をIDグループごとに行います。
データ
data have;
input @1 item @4 id @8 price_mark @13 price;
datalines;
1 234 1000 400
2 234 1000 450
3 234 1000 1000
4 234 1000 1000
5 234 1000 1000
6 234 1000 1000
7 234 1000 760
8 234 1000 430
9 234 1000 500
10 234 1000 1000
11 234 1000 1000
12 234 1000 500
13 234 1000 360D
3 321 500 420
4 321 500 500
5 321 500 500
6 321 500 500
7 321 500 500
8 321 500 300
9 321 500 450
10 321 500 300
;
run;
Hash Objectで考えると
1. 利用額が限度額を超えるまでのイベントをbooleanフラグで判定する変数を宣言する
2. 1のフラグをカウントする変数を宣言する
3. 1,2の変数をHASH objectのキーとして設定する
4. データセットを読み込んでキーの存在チェックを行い、存在しない場合は2の変数を1増分してHash Objectsに代入する
5. 一回目のフラグはカウントしないのでIF文で不明値を代入
6. 5の条件以外でフラグがtrueの場合にカウントを実行する
7. 6の条件に当てはまらないオブザベーションは不明値を入力する
4のステップでキーの存在チェックとHash Objectsへのキーの挿入を同時に行うことでデータステップでよく使用するLAG関数を使用した面倒なロジックを排除することができます。一見ロジックが多くまどろっこしい印象を受けますが、ステップ3,4のフラグ変数をグループとして動的にHash Objectに定義して処理できることを覚えてしまうと今後のデータステップのコーディングが楽になるかもしれません。
data want;
if _N_=1 then do;
dcl hash h();
*3;
h.definekey("id","_iorc_","_flg");
h.definedone();
end;
do until(last.id);
set have;
by id;
*1;
_iorc_=(price_mark ne price);
*2,4;
if h.check() ne 0 then do;
_flg+1;
h.replace();
if first.id then _flg=1;
end;
*5;
if _iorc_=1 and _flg=1 then flg=.;
*6;
else if _iorc_=1 then flg+1;
*7;
else if _iorc_=0 then flg=.;
output;
end;
h.clear();
drop _flg;
run;
出力結果

|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/1f982dec.eb959046.1f982ded.24d6f658/?me_id=1295925&item_id=10000028&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fseiseisui%2Fcabinet%2Fi%2Fimgrc0072351369.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

COVID19データを分析する-週別
前回に引き続きCOVID19データを分析します。
今回は取り込んだCOVID19データの週の何曜日から連続して感染者が発生しているかカウントします。
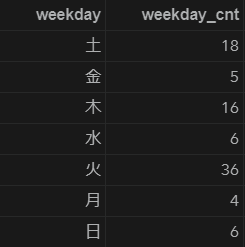
こうしてみると火曜日、木曜日、土曜日始まりのケースが目立ちますね。
サラリーマンの通勤行動に何かしら因果関係があるのでしょうか。
前回の連続感染者の増加がみられたケースの集計結果をstart_dateのweekdayのカテゴリで集計してみた結果になります。
プログラム
filename resp "/home/xxxxxxx/excel/covid.txt";
proc http url='https://covid.ourworldindata.org/data/owid-covid-data.json'
method="GET" out=resp;
run;
/* Assign a JSON library to the HTTP response */
libname space JSON fileref=resp;
*assign country;
%let cntry=JPN;
data have;
drop ordinal:;
retain year month day _date dif_new_cases;
set space.&cntry._data;
by date;
format _date yymmdds10.;
dif_new_cases=dif(new_cases);
_date=input(date, yymmdd10.);
year=year(_date);
month=month(_date);
day=day(_date);
output;
drop date;
rename _date=date;
run;
data out;
length year month day max_dif_new_cases max_dif_new_cases_date max_new_cases
max_new_cases_date max_new_deaths max_new_deaths_date max_stringency_index
max_stringency_index_date 8;
format date max_dif_new_cases_date max_new_cases_date max_new_deaths_date
max_stringency_index_date yymmdds10.;
do until(last.month);
set have end=lr curobs=_r;
by month notsorted;
if max_dif_new_cases < dif_new_cases then
do;
max_dif_new_cases=dif_new_cases;
max_dif_new_cases_date=date;
end;
if max_new_cases < new_cases then
do;
max_new_cases=new_cases;
max_new_cases_date=date;
end;
if max_new_deaths < new_deaths then
do;
max_new_deaths=new_deaths;
max_new_deaths_date=date;
end;
if max_stringency_index < stringency_index then
do;
max_stringency_index=stringency_index;
max_stringency_index_date=date;
end;
end;
drop new_cases-numeric-new_tests_per_thousand tests_units;
run;
data want;
length year month day dif_new_cases max_dif_new_cases max_dif_new_cases_date
new_cases max_new_cases max_new_cases_date new_deaths max_new_deaths
max_new_deaths_date stringency_index max_stringency_index
max_stringency_index_date 8;
format date max_dif_new_cases_date max_new_cases_date max_new_deaths_date
max_stringency_index_date yymmdds10.;
do until(last.month);
set have;
by month notsorted;
dif_new_cases=ifn(first.month, ., dif_new_cases);
if max_dif_new_cases < dif_new_cases then
do;
max_dif_new_cases=dif_new_cases;
max_dif_new_cases_date=date;
end;
if max_new_cases < new_cases then
do;
max_new_cases=new_cases;
max_new_cases_date=date;
end;
if max_new_deaths < new_deaths then
do;
max_new_deaths=new_deaths;
max_new_deaths_date=date;
end;
if max_stringency_index < stringency_index then
do;
max_stringency_index=stringency_index;
max_stringency_index_date=date;
end;
end;
do until(last.month);
set have;
by month notsorted;
output;
end;
drop new_cases-numeric-new_tests_per_thousand tests_units;
run;
options fullstimer locale=en_us;
*連続感染者の推移をランキング出力;
data consecevt(keep=con_cases exact_count total_count)
consecevt_detail(keep=start_date end_date con_cases weekday)
weekday_cnt(keep=weekday con_cases start_date weekday_cnt);
if _N_=1 then do;
if 0 then set want;
dcl hash consecevt(ordered:"d",suminc:"exact_count",multidata:"y")
consecevt_det(ordered:"d",suminc:"exact_count",multidata:"y")
out1(multidata:"y",ordered:"d")
out2(multidata:"n",ordered:"d")
out3(multidata:"y",ordered:"d");
consecevt.definekey("con_cases");
consecevt.definedata("con_cases","year","month","day");
consecevt.definedone();
consecevt_det.definekey("con_cases");
consecevt_det.definedata("con_cases","year","month","day");
consecevt_det.definedone();
out1.definekey("con_cases");
out1.definedata("con_cases","exact_count","total_count");
out1.definedone();
out2.definekey("start_date");
out2.definedata("start_date","end_date","con_cases");
out2.definedone();
out3.definekey("weekday");
out3.definedata("weekday","con_cases","start_date");
out3.definedone();
dcl hiter ci("consecevt_det") out2i("out2") out3i("out3");
end;
format start_date end_date yymmdds10.;
con_cases=0;
do until(last.month);
set want end=lr;
by year month notsorted;
con_cases=ifn(sign(dif_new_cases)=1,con_cases+1,0);
if sign(dif_new_cases)=1 then consecevt.ref();
if con_cases then consecevt_det.add();
end;
if lr;
retain exact_count 1;
total_adjust=0;
*感染者推移ランキング;
do con_cases=consecevt.num_items to 1 by -1;
consecevt.sum(sum:exact_count);
total_count=exact_count+total_adjust;
output consecevt;
total_adjust+exact_count;
end;
*詳細;
do while(ci.next()=0);
end_date=mdy(month,day,year);
start_date=end_date-con_cases+1;
_iorc_=out2.add();
end;
if lr;
do while(out2i.next()=0);
weekday=weekday(start_date);
_iorc_=out3.add();
output consecevt_detail;
end;
if lr;
do while(out3i.next()=0);
weekday_cnt=ifn(lag(weekday) ne weekday,1,sum(weekday_cnt,1));
output weekday_cnt;
end;
run;
*曜日表示用出力形式;
proc format;
picture mywk(default=10)
1="日"
2="月"
3="火"
4="水"
5="木"
6="金"
7="土"
;
run;
*上のコードに次期に修正する予定;
data weekday_cnt(keep=weekday weekday_cnt);
do until(last.weekday);
format weekday mywk.;
set weekday_cnt;
by weekday notsorted;
end;
run;
*csvファイル作成マクロ;
%macro callcsv(filename,dsn);
ods csv file="&filename";
proc print data=&dsn noobs;
title "consecevt";
footnote "&sysdate";
run;
ods csv close;
%mend;
*csvファイル作成バッチ;
data _null_;
infile datalines dlm="09"x;
input filename:$200. dsn:$50.;
*_iorc_=dosubl(cats('%callcsv(',filename,',',dsn,')'));
call execute(cats('%callcsv(',filename,',',dsn,')'));
datalines;
/home/xxxxxxx/excel/consecevt.csv consecevt
/home/xxxxxxx/excel/consecevt_detail.csv consecevt_detail
/home/xxxxxxx/excel/weekday_cnt.csv weekday_cnt
;
run;
COVID19データを分析する
今回は取り込んだCOVID19データを分析するプログラムを紹介します。
下のプログラムは連続感染者数が数を問わず増加しているケースを集計し、結果と詳細を出力しています。
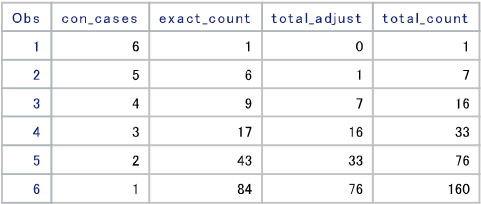
上の例は11月27日までの集計結果です。
con_casesが連続感染者数の増加が1日から6日まで連続したケースを表し、
exact_countで各々のケースの数を集計しています。
total_countは積み上げの集計結果でtotalで160件になります。
各々のケースは下の詳細表で確認できます。最高連続感染者の増加が計測されたのは7月1日から7月6日までのケースで、11月から連続感染者の増加傾向が強いようです。
7月1日は緊急事態宣言が解除された後で全国で外出が目立ちましたし、11月はgotoキャンペーンで同じく外出の増加が計測されたためにこのような結果が計測されています。
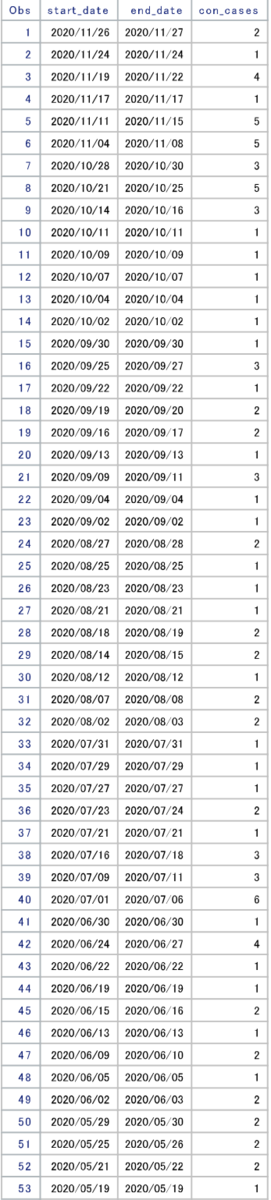
詳しい詳細は省きますが、hash objectのsumincメソッドを使用して連続感染者の増加がみられたケースをカテゴリ分けし各々のケースが発生したイベントの回数を集計しています。
プログラム
filename resp temp;
proc http url='https://covid.ourworldindata.org/data/owid-covid-data.json'
method="GET" out=resp;
run;
/* Assign a JSON library to the HTTP response */
libname space JSON fileref=resp;
*assign country;
%let cntry=JPN;
data have;
drop ordinal:;
retain year month day _date dif_new_cases;
set space.&cntry._data;
by date;
format _date yymmdds10.;
dif_new_cases=dif(new_cases);
_date=input(date, yymmdd10.);
year=year(_date);
month=month(_date);
day=day(_date);
output;
drop date;
rename _date=date;
run;
data want;
length year month day dif_new_cases max_dif_new_cases max_dif_new_cases_date
new_cases max_new_cases max_new_cases_date new_deaths max_new_deaths
max_new_deaths_date stringency_index max_stringency_index
max_stringency_index_date 8;
format date max_dif_new_cases_date max_new_cases_date max_new_deaths_date
max_stringency_index_date yymmdds10.;
do until(last.month);
set have;
by month notsorted;
dif_new_cases=ifn(first.month, ., dif_new_cases);
if max_dif_new_cases < dif_new_cases then
do;
max_dif_new_cases=dif_new_cases;
max_dif_new_cases_date=date;
end;
if max_new_cases < new_cases then
do;
max_new_cases=new_cases;
max_new_cases_date=date;
end;
if max_new_deaths < new_deaths then
do;
max_new_deaths=new_deaths;
max_new_deaths_date=date;
end;
if max_stringency_index < stringency_index then
do;
max_stringency_index=stringency_index;
max_stringency_index_date=date;
end;
end;
do until(last.month);
set have;
by month notsorted;
output;
end;
drop new_cases-numeric-new_tests_per_thousand tests_units;
run;
*連続感染者の推移をランキング出力;
data consec_event;
if _N_=1 then do;
if 0 then set want;
dcl hash consecevt(ordered:"d",suminc:"exact_count");
consecevt.definekey("con_cases");
consecevt.definedata("con_cases","year","month","day");
consecevt.definedone();
end;
con_cases=0;
do until(last.month);
set want end=lr;
by year month notsorted;
con_cases=ifn(sign(dif_new_cases)=1,con_cases+1,0);
if sign(dif_new_cases)=1 then consecevt.ref();
end;
if lr;
retain exact_count 1;
total_adjust=0;
do con_cases=consecevt.num_items to 1 by -1;
consecevt.sum(sum:exact_count);
total_count=exact_count+total_adjust;
output;
total_adjust+exact_count;
end;
keep con_cases--total_count;
run;
*連続感染者の推移の詳細を時系列で出力;
data consec_event_detail;
if _N_=1 then do;
if 0 then set want;
dcl hash consecevt(multidata:"y",ordered:"d") out(multidata:"n",ordered:"d");
consecevt.definekey("con_cases");
consecevt.definedata("con_cases","year","month","day");
consecevt.definedone();
*重複キーを除外;
out.definekey("start_date");
out.definedata("start_date","end_date","con_cases");
out.definedone();
dcl hiter ci("consecevt") outi("out");
end;
format start_date end_date yymmdds10.;
con_cases=0;
do until(last.month);
set want end=lr;
by year month notsorted;
con_cases=ifn(sign(dif_new_cases)=1,con_cases+1,0);
if con_cases then consecevt.add();
end;
if lr;
do while(ci.next()=0);
end_date=mdy(month,day,year);
start_date=end_date-con_cases+1;
_iorc_=out.add();
end;
if lr;
do while(outi.next()=0);
output;
end;
drop dif: max: year month day;
run;
SASでJSONデータを取り込む
JSON形式のデータはPROC HTTPとJSON形式のライブラリ参照で取得することができます。
例:
------------------------------------------------------------------------------------------
filename resp 〈ファイル参照名〉;
proc http url='<JSON-URL>' method="GET" out=resp;
run;
libname space JSON fileref=resp;
------------------------------------------------------------------------------------------
上の例ではSPACEという名前のライブラリ名でJSON形式のライブラリに関連するデータセットが作成されます。今回は試しにWHOのサイトからCOVID19データを JSON形式でダウンロードして月別の感染者の最大増加を表すデータセットを作成してみます。
COVID19のJSON形式のファイルはourworldindata.orgからダウンロード可能です。
上のURLのJSONリンクをクリックするとURLが表示されますので先ほどのコードに張り付けて実行することでSPACEという名前のライブラリにCOVID関連のデータセットが表示されます。
------------------------------------------------------------------------------------------
filename resp 〈ファイル参照名〉;
proc http url='https://covid.ourworldindata.org/data/owid-covid-data.json' method="GET" out=resp;
run;
libname space JSON fileref=resp;
------------------------------------------------------------------------------------------

filename resp temp;
proc http url='https://covid.ourworldindata.org/data/owid-covid-data.json'
method="GET" out=resp;
run;
/* Assign a JSON library to the HTTP response */
libname space JSON fileref=resp;
*assign country;
%let cntry=JPN;
data have;
drop ordinal:;
retain year month day _date dif_new_cases;
set space.&cntry._data;
by date;
format _date yymmdds10.;
dif_new_cases=dif(new_cases);
_date=input(date, yymmdd10.);
year=year(_date);
month=month(_date);
day=day(_date);
output;
drop date;
rename _date=date;
run;
data out;
length year month day max_dif_new_cases max_dif_new_cases_date max_new_cases
max_new_cases_date max_new_deaths max_new_deaths_date max_stringency_index
max_stringency_index_date 8;
format date max_dif_new_cases_date max_new_cases_date max_new_deaths_date
max_stringency_index_date yymmdds10.;
do until(last.month);
set have end=lr curobs=_r;
by month notsorted;
if max_dif_new_cases < dif_new_cases then
do;
max_dif_new_cases=dif_new_cases;
max_dif_new_cases_date=date;
end;
if max_new_cases < new_cases then
do;
max_new_cases=new_cases;
max_new_cases_date=date;
end;
if max_new_deaths < new_deaths then
do;
max_new_deaths=new_deaths;
max_new_deaths_date=date;
end;
if max_stringency_index < stringency_index then
do;
max_stringency_index=stringency_index;
max_stringency_index_date=date;
end;
end;
drop new_cases-numeric-new_tests_per_thousand tests_units;
run;
_N_自動変数
今回は自動変数_N_について紹介します。
自動変数とは
自動変数とはSASデータセットを読み込んだ際に自動で作成される変数です。
データセットには出力されずSETステートメントで指定したデータセットの読み込み終了後には自動で削除されます。
初期値は1でdata ステートメントを通る度に1ずつ増分します。
イメージとしては以下の図のようになります。

上記のイメージから分かる通りDATAステートメントを通る度に_N_のカウンタが増分するため、ある種ステートメントがDOループの働きをしています。
DATAステップでのDOループ
DATAステップがDOループの働きをしているということは同ステップ内でDOループを使用した場合、通常のプログラミング言語と同じように_N_変数はouter loop、DOループ内で使用しているカウンタ変数はinner loopの動きをするということになります。

上の図では_N_がouter loop、ridがinner loopになります。setステートメントで使用しているcurobsオプションは読み込んだデータセットのオブザベーションのカウンタを保存します。オプションで指定しているrid変数がinner loopになります。
_N_は読み込んだデータセット数分しか増分しません。上の例は1です。
ridはinner loopになりますのでオブザベーション数分増分します。上記の例では疑似的に10オブザベーションにしています。下のsashelp.classを使用した例でみるとわかりやすいかと思います。
例:
data work.aaa;
do until(eof);
set sashelp.class curobs=rid end=eof;
put _all_;
end;
run;
結果
_N_=1 rid=1
_N_=1 rid=2
_N_=1 rid=3
_N_=1 rid=4
_N_=1 rid=5
_N_=1 rid=6
_N_=1 rid=7
_N_=1 rid=8
_N_=1 rid=9
_N_=1 rid=10
_N_=1 rid=11
_N_=1 rid=12
_N_=1 rid=13
_N_=1 rid=14
_N_=1 rid=15
_N_=1 rid=16
_N_=1 rid=17
_N_=1 rid=18
_N_=1 rid=19
PUTの結果のみ表示しておりますが、データセットとしては1件しか表示されません。なぜか?_N_がループしていないためです。
次回はこの特徴を使用したループの使用方法を解説します。
Hash Object VS SQL
前回に引き続きSASのHash Objectについて紹介します。
FULL Join

- 目的
前回に引き続きFIND()メソッドを使用してprimaryデータセットに対してsecondaryデータセットのオブザベーションを追加更新します。
FULL JOINなのでSecondaryのデータセットに対してもFINDメソッドでprimaryデータセットを追加更新しますが、今回は加えてFIND_NEXTメソッドを使用します。
- FIND_NEXTメソッド
FINDメソッドはルックアップ先のデータセット(下の例ではsecondary)に重複キーが存在する場合、最初の1オブザベーションのデータのみ追加します。そのため下の例のように重複キーが存在するsecondaryデータセットを一意のキーのみ存在するprimaryデータセットで検索して更新する場合、重複キー内のデータを各々検索更新する必要があります。これを実装するのがFIND_NEXTメソッドです。
b.find_next()
- ルックアップ方法
secondaryデータセットに対してもFINDメソッドでprimaryデータセットの内容で更新することをそのまま実装するとsecondaryデータセットもdatasetタグでハッシュオブジェクトを宣言することになりますが、これを実装すると余計なデータセットの入力が増えてしまうためパフォーマンスに影響を及ぼすのと、コードが見づらくなります。
そのため、secondaryデータセットに対しては空のハッシュオブジェクトを宣言し、primaryデータセットに対してルックアップを行ったタイミングでsecondaryデータセットの内容を空のハッシュオブジェクトに追加してあげると余計なデータセットの入力が抑えられ、コードもまとまります。
declare hash x();*1
x.definekey("key");
x.definedone();
.
.
.
set primary end=eof;
x.replace();
上のreplaceメソッドはprimaryデータセットの内容をハッシュオブジェクトxにキーのみ追加しています。後のsecondaryデータセットとのルックアップにてprimaryデータセットとキーを照合するために使用します。
replaceメソッドの次のコードではprimaryデータセットとsecondaryデータセットとの照合でキーが見つからなかった場合データを欠損値にします。
if b.find() ne 0 then
call missing(bdata);*2
output;
最後にprimaryデータセットとsecondaryデータセットのルックアップを実行します。
上のsetステートメントでprimaryデータセットを読み込んだキーのデータをfind_nextメソッドでルックアップしています。
do while(b.find_next()=0);*3;
output;
end;
残ったsecondaryデータセットとprimaryデータセットのルックアップですが、こちらはiteratorを使用してルックアップを実行します。
iteratorとはHash object単体でループとして使用できるオブジェクトになり、while文でiteratorのnext()がtrueの間のループでHash objectxとルックアップを行っています。
declare hiter IB("b");*1;
.
.
.
do while(ib.next()=0);
if x.check() ne 0 then
output;
end;
例:Hash ObjectでのFULL JOIN
data primary;
input key adata;
cards;
1 1
2 2
3 3
4 4
5 5
6 6
7 7
;
run;
data secondary;
input key bdata;
cards;
1 11
1 12
1.5 1.51
3 31
4 4
6 61
6 62
6 63
6.5 6.51
6.5 6.52
7 7
;
run;
data c;
if 0 then
set secondary;
declare hash b(dataset:"secondary", multidata:"y");
declare hiter IB("b");*1;
b.definekey("key");
b.definedata("key", "bdata");
b.definedone();
declare hash x();*1
x.definekey("key");
x.definedone();
do until(eof);
set primary end=eof;
x.replace();*1
if b.find() ne 0 then
call missing(bdata);*2
output;
do while(b.find_next()=0);*3;
output;
end;
end;
call missing(adata);
do while(ib.next()=0);
if x.check() ne 0 then
output;
end;
stop;
run;
Hash Object VS SQL
SASのHash ObjectをSQLと比較したものを記事にしました。
-
SQLとの比較
以前の記事に書いた通り、 SASのHash Objectはプログラム実行時にデータセットをメモリに格納し、キー、データの単位でテーブルルックアップを実行するオブジェクトになります。(下図参照)

Hash Objectのテーブルルックアップは基本的にFIND()メソッドを実行し、Left joinの挙動でルックアップを実行します。
set <データセットA>;
rc=<データセットB>.find();
上記の例ではデータセットAに対してデータセットBの変数の内容で更新をします。
SQLでは実行文に項目名の羅列が必要ですが、Hash Objectではその必要がありません。
今回はHash ObjectのテーブルルックアップをSQLのJOINに置き換えた場合を想定して掲載しております。それでは見ていきましょう。
Left Join

下の例はHash ObjectでLeft Joinをしたものになります。FIND()メソッドを使用してprimaryデータセットに対してsecondaryデータセットのオブザベーションを追加更新しています。
_iorc_=sec.find();
ちなみに上の_IORC_変数は宣言してもSASデータセットに直接書き込まれない自動変数です。SASシステム内で管理されている変数でありユーザが直接更新しても内部で保持しているカウンタに影響せず、かつ使用後にdropする必要がなく大変便利なので使用しています。
if _iorc_ ne 0 then call missing(y);
call missingステートメントではFIND()メソッドで合致しなかったオブザベーションに欠損値を代入しています。
例:Hash Objectでルックアップ
data primary;
input number;
cards;
10001
10002
10009
10003
10004
10005
;
run;
data secondary;
input number y;
cards;
10001 11
10003 12
10004 13
10005 17
;
run;
data main;
if _N_=1 then
do;
if 0 then
set secondary;
dcl hash sec(dataset:"secondary") x();
sec.definekey("number");
sec.definedata("number", "y");
sec.definedone();
x.definekey("number");
x.definedata("number", "y");
x.definedone();
dcl hiter seci("sec");
end;
set primary;
_iorc_=sec.find(); *1;
if _iorc_ ne 0 then call missing(y);*2;
run;
Inner Join

下の例はHash ObjectでInner Joinをしたものになります。FIND()メソッドを使用して
値が0、つまり結合対象のデータセット双方に合致するオブザベーションのみを出力しています。
if _iorc_ = 0 then output;
data primary;
input number a;
cards;
10001 1
10002 2
10009 9
10003 3
10004 4
10005 5
;
run;
data secondary;
input number b;
cards;
10001 11
10003 12
10004 13
10005 17
;
run;
data main;
if _N_=1 then
do;
if 0 then
set secondary;
dcl hash sec(dataset:"secondary") x();
sec.definekey("number");
sec.definedata("number", "b");
sec.definedone();
x.definekey("number");
x.definedata("number", "a");
x.definedone();
dcl hiter seci("sec");
end;
set primary;
_iorc_=sec.find();*1;
if _iorc_ = 0 then output;*2;
run;
次回はFULL JOINについて詳しく紹介します。